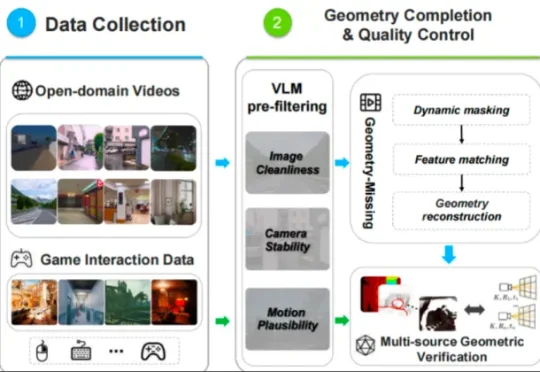
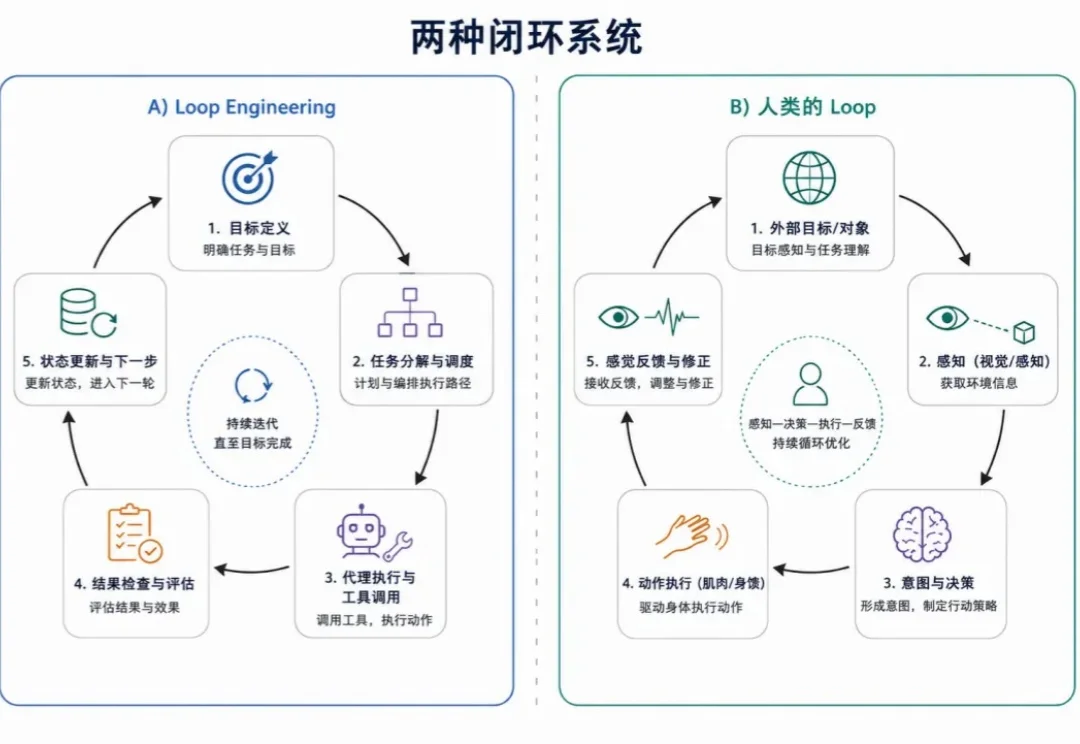
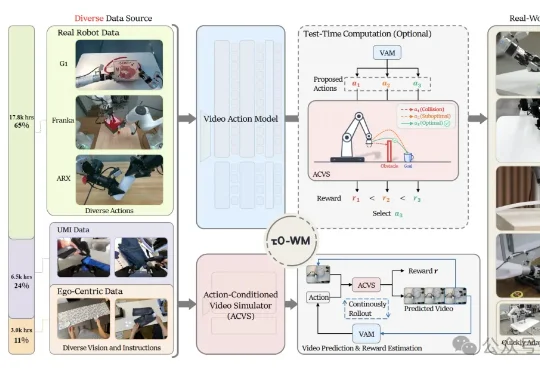
六位顶尖学者、三大挑战赛道——IROS 2026 Physical World Models Workshop征稿
六位顶尖学者、三大挑战赛道——IROS 2026 Physical World Models Workshop征稿2026年10月1日,IROS 2026 Workshop——Physical World Models for Scaling Embodied AI将在美国匹兹堡举行。论文征集现已开放,8月10日截止;WorldArena 2.0 Challenge三大赛道已于7月10日开赛,总奖金$7500。
来自主题: AI资讯
6899 点击 2026-07-22 10:09